Background &
Objective
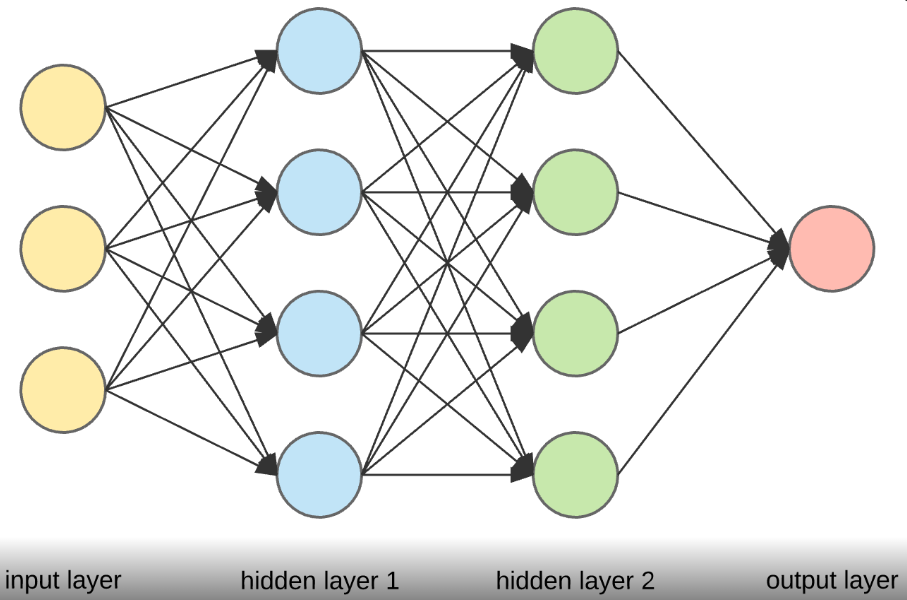
These three Problem Based Learning projects explore complementary neural network architectures, each tackling a distinct domain. Two studies address the same regression challenge Tabular Regression (Healthcare Analytics) predicting medical insurance charges from emographic and health factors using a Multi-Layer Perceptron (MLP). The primary objective is to develop a predictive model that estimates insurance charges based on various demographic and health-related factors such as age, bmi, smoking status, and region. The Radial Basis Function (RBF) model, a powerful machine learning approach, is used to train and predict insurance costs by capturing complex patterns in the data., allowing a direct architectural comparison on identical data.
The third study shifts to computer vision: a custom Convolutional Neural Network (CNN) trained from scratch to classify coastal objects that are shells versus pebbles working across a dataset of over 4,000 labelled images. Developed the CNN model for binary image classification, trained on a dataset containing two distinct image categories. The model achieved a training accuracy and a validation accuracy demonstrating its ability to learn meaningful patterns from image data and generalize to unseen samples with minimal overfitting. Together, the three projects cover the breadth of supervised ML, from tabular regression to image classification.
All models were trained, evaluated, and documented end-to-end: dataset preprocessing, architecture design, training runs, and performance analysis against standard metrics (MSE, R², accuracy, precision/recall). The common thread is understanding how different inductive biases, dense layers, kernel transformations, and spatial convolutions shape what a model learns and how well it generalises.
- Year2024 - 2025
- TypeProblem Based Learning (PBL)
- Team6 Members
- GuideDr. Rashmi P. Shetty
- DatasetsKaggle · Medical Insurance & Coastal Images
- StackPython · Scikit-learn · TensorFlow · Keras
- InstituteNMAM Institute of Technology, NITTE